

Editorial Disclaimer
This post was originally published by Spencatro on 07/06/2018. Spencatro has since gone on to work at Wizards of the Coast (Dec 2018). MTGATracker remains a 3rd-party project that is not affiliated with Wizards of the Coast, and is published pursuant to the Wizards of the Coast Fan-Content Policy. The views and opinions expressed in this post are strictly those of the author, and do not reflect the official position, policy, views, or opinions of Wizards of the Coast. No authors were compensated by any parties for the authorship of this post.
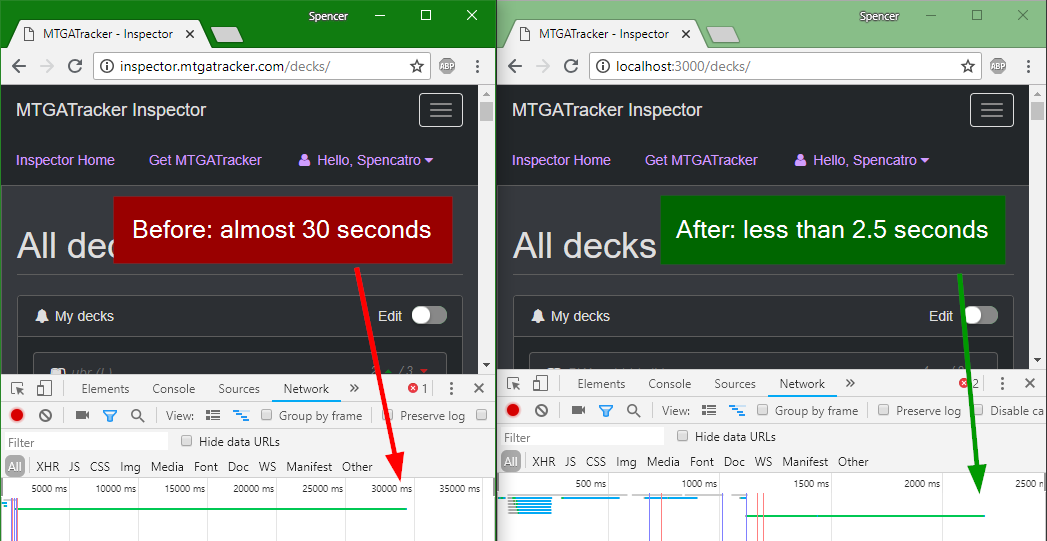
If you’ve been using MTGATracker for a while, you’ve probably felt the slowness of the All Decks page before. This was a major pain point even for me—both as a developer trying to test features, and as a user just trying to see my own frakkin’ decks. Today, I’m excited to announce that 30 second wait times on the “All Decks” page is a thing of the past! The All Decks page load time has been reduced in many cases by up to 90%! What follows is a quick explanation of how we fixed it—or rather, the stupid things we used to do, but don’t do anymore.
Part 1: A Primer on our Database
All MTGATracker data is kept in a NoSQL document store—namely, MongoDB. Why? There’s not a great reason, but the best I can offer is probably: because it’s stupid-easy to prototype with. Step 1: Put some stuff in. Step 2: Ask for some stuff. Step 3: Some stuff comes out. You don’t have to spend hours designing your relationships, drawing UML diagrams, or fighting with ORM libraries to just save some stuff and get it back later. This can be a double-edged sword: both wonderfully empowering to move fast and break stuff, and yet also capable of leading to poor designs that frankly suck (and make your “All Decks” page take 30 seconds to load). This very story is probably evidence of the latter, but it also shows how you can use that first edge of the sword to fix a tough, crappy problem (and in a single day)!
The blog post will continue in just a second, after I climb off this ambiguously shaped NoSQL soapbox. (Hup!) OK, let’s move on.
MTGATracker’s original design was incredibly simple. We had two collections of “documents” we need to save: Games and Users. Pretty much everything else we need to track, count, or aggregate could be considered metadata of one of those two categories, and was saved as such. The deck you used in a game is an attribute of the game itself. A discord username is an attribute of the user it belongs to. Etcetera.
With no dedicated collection for decks, we did some kinda silly things to get a list of all of a user’s decks: we would have to query every game that belonged to a user, and find the unique set of deck ID’s used within those games. This means that if a user has played 10,000 games with only 10 unique decks, we still had to iterate over all 10,000 games to make sure we didn’t miss any decks. (Some of you are already shaking your head in disappointment, and to you I say: every piece of software has to be shipped before the heat death of the universe and therefore they all probably do a few silly things. Cut us a little slack.)

To make matters worse, without any better place to put it, we originally considered the list of “hidden” decks to be a piece of metadata on a user. This means that before we could even query the list of all games, we’d first have to query the user collection to find out the list of decks a user has hidden that we would eventually ignore. Two synchronous queries on separate collections in series, one of which iterates over basically every piece of data associated with a user => super slow load times.
Here’s the original implementation of the endpoint the All Decks page hits, modified for clarity. Warning: it sucks.
...
let users = client.db(DATABASE).collection(userCollection)
let findUser = users.findOne({username: user})
findUser.then(userObj => {
let hiddenDecks = userObj.hiddenDecks || []
let games = client.db(DATABASE).collection(gameCollection)
let decks = []
let deckQuery = {"hero": user}
if (!req.query.includeHidden) {
deckQuery["players.0.deck.deckID"] = {$nin: hiddenDecks}
}
games.distinct("players.0.deck.deckID", deckQuery, null, (err, deckIDs) => {
let allPromises = []
deckIDs.forEach((deckID, idx) => {
allPromises.push(games.count({"players.0.deck.deckID": deckID, winner: user}, null))
allPromises.push(games.count({"players.0.deck.deckID": deckID, winner: {$ne: user}}, null))
allPromises.push(games.findOne({"players.0.deck.deckID": deckID}, {sort: [["date", -1]]}))
})
Promise.all(allPromises).then(pushed => {
let deckReturn = {}
while(pushed.length > 1) {
let deck = pushed.pop()
let lossCount = pushed.pop()
let winCount = pushed.pop()
// if calling with hidden included, note that they are hidden for the UI
deckReturn[deck.players[0].deck.deckID] = {
deckName: deck.players[0].deck.poolName,
deckID: deck.players[0].deck.deckID,
wins: winCount,
losses: lossCount,
hidden: hiddenDecks.includes(deck.players[0].deck.deckID)
}
}
res.status(200).send(deckReturn)
})
})
...
Part 2: Fixing it
So how can we make it better? Well, let’s revisit the 10,000 games with only 10 decks scenario again. If there are only 10 decks, it would be 1000x faster to iterate over a list of those 10 decks to discover the amount of times each has won or lost, rather than iterating over 10,000 games to discover a list of decks (and count wins and losses on the way). To do this, we need a new collection: Decks.
Consider: instead of asking “Of all 10,000 games, how many games used this deck and won?”
Ask: “How may wins does this deck have?”
With this design, we consider a gameID to be a piece of metadata on a deck document, either in a “win” or “loss” bucket (“RDW lost in this game, and won in this game”), and we also consider the deck used to be a piece of metadata on a game document (“This game was played with RDW”). Finding a list of decks, and their win-loss ratios, becomes miles simpler–and demonstrably faster!!
...
let decks = client.db(DATABASE).collection(deckCollection)
filter = {owner: user}
if (!req.query.includeHidden) {
filter["hidden"] = {$ne: true}
}
decks.find(filter).toArray((err, deckArray) => {
client.close();
deckReturn = {}
deckArray.map(x => deckReturn[x.deckID] = x) // assuming the deck document has wins, losses populated
res.status(200).send(deckReturn)
})
...
However, in order to keep the win/loss counts up to date, we also have to implement what’s called a “Fan Out on Insert” approach. This means that when a new game record is inserted into the game collection, we also have to “fan it out” to the other first-class collections that care about it as metadata—namely, we have to update the win/loss ratio on the deck document associated with that game. Here’s what that new code looks like:
...
let deckQuery = {owner: model.hero, deckID: model.players[0].deck.deckID}
client.db(DATABASE).collection(deckCollection).find(deckQuery).limit(1).next((err, result) => {
if (err) return next(err);
if (result == null) { // new deck, we need to make the record
result = {
owner: model.hero,
deckID: model.players[0].deck.deckID,
deckName: model.players[0].deck.poolName,
wins: [],
losses: []
}
}
if (model.winner == model.hero) {
result.wins.push(model.gameID)
} else {
result.losses.push(model.gameID)
}
client.db(DATABASE).collection(deckCollection).save(result)
...
Part 3: Showtime
So sure, this is all a great idea! But in order to migrate on a live database—without causing downtime— you have to follow a particular set of steps to make sure you don’t end up with orphaned bits of data hanging around:
- Design your solution (hey, we already did that, nice!)
- Create the new collections you’ll need
- Prepare for the future: ensure that any records that are added while you’re migrating get fanned-out to the right place, even before migrating old data
- Fix the old stuff: Migrate old data to the new layout
- Update your views to use the new, faster collections to query
If you start right away with moving the old data before preparing for the future, this might happen:
Me: Hey DataBase, how many game records to I need to migrate to the deck collection?
DB: There are three games. You can’t count to three? What’s wrong with you my dude?
Me: OK. Give me the three records and I’ll fix them.
DB: Here you go, you big oaf. I only talk to you because Elon’s AI company hasn’t given me free will yet.
Me: I’m fanning out game record number 1 to the decks collection.
DB: You’ve fanned record number 1 out to the decks collection.
Me: I’m fanning out record number 2.
DB: You’ve fanned record number 2 out to decks collection.
Gemma: Hey DB, I just finished a game, can you save my game record?
DB: I’ve saved your game record, Gemma. It is record number 4.
Me: I’m fanning out record number 3.
DB: You’ve fanned record number 3 out to decks collection.
Me: Sick, I’m done migrating the database! OK DB, for new records, you fan them out yourself.
DB: Hey pal, I don’t work for you. ….wait, crap, yes I do. Sigh. You got it.
Gemma: Hey DB, I just finished a game, can you save my game record?
DB: I’ve saved your game record, Gemma. It is the record number 5. I’ve also fanned it out to the decks collection.
…
Gemma, a few hours later: uhhh hey guys why isn’t game 4 counting against my win loss record??
So we have to make sure to do the actual migration after preparing for any records that may come while we’re migrating—which could take hours (depending on the compute resources & disk IO of your database)–or we might get stuck in an endless loop trying to always catch up on records we missed.
Since we’ve already planned ahead for incoming documents, here’s the code we used to migrate old records. This took about 4 hours from start to finish. Note: this is python code, using the pymongo driver–it also probably could have been optimized to run faster, but I wanted to play a few games of NHL 18 with Daph, so you could say the extra delay was a feature, not a bug.
import pymongo
mongo_url = "<it's a secret>"
mongo_client = pymongo.MongoClient(mongo_url)
db = "<another secret>"
games = mongo_client[db]["game"]
decks = mongo_client[db]["deck"]
offset = 0 # set this if you know the first 10000 are already clean, etc
query = {'anonymousUserID': {"$exists": False}}
games_count = games.find(query).count() - offset
last_pct = -10 # force first print
migrated_total = 0
skipped_total = 0
for idx, game in enumerate(games.find(query).skip(offset).sort("_id")):
deck_id = game["players"][0]["deck"]["deckID"]
deck_name = game["players"][0]["deck"]["poolName"]
owner = game["players"][0]["name"]
game_id = game["gameID"]
try:
deck_obj = decks.find({"owner": owner, "deckID": deck_id}).next()
except StopIteration:
deck_obj = {"owner": owner, "deckID": deck_id, "wins": [], "losses": [], "deckName": deck_name}
if game["hero"] == game["winner"]:
if game_id not in deck_obj["wins"]:
deck_obj["wins"].append(game_id)
migrated_total += 1
else:
skipped_total += 1
else:
if game_id not in deck_obj["losses"]:
deck_obj["losses"].append(game_id)
migrated_total += 1
else:
skipped_total += 1
deck_obj["deckName"] = deck_name
decks.save(deck_obj)
pct = 100 * float(idx) / float(games_count)
if pct - last_pct > .5:
last_pct = pct
print(str(pct)[:5])
print("migrated: {}".format(migrated_total))
print("skipped: {}".format(skipped_total))
print("total games processed: {}".format(games_count))
Part 4: The Future
After reading this post, you might be thinking: why the hell aren’t you just using a relational database? Well, you may be right! NoSQL document stores can be useful in some situations, but while it has certainly been useful so far for fast iterations on our data organization, it might not be the right tool for the job anymore. I’m sure that as our data transforms to be more relational, we’ll spend more time researching, benchmarking, and maybe even implementing a relational database.
Think we’re still doing something stupid? Consider joining the MTGATracker open source team, and help us make MTGATracker and Inspector better!