

Editorial Disclaimer
This post was originally published by Spencatro on 11/28/2018. Spencatro has since gone on to work at Wizards of the Coast (Dec 2018). MTGATracker remains a 3rd-party project that is not affiliated with Wizards of the Coast, and is published pursuant to the Wizards of the Coast Fan-Content Policy. The views and opinions expressed in this post are strictly those of the author, and do not reflect the official position, policy, views, or opinions of Wizards of the Coast. No authors were compensated by any parties for the authorship of this post.
There are some big changes in the works for MTGATracker & Inspector coming soon! (To be honest, probably a little sooner than we’d like). This post is to explain what’s happening, and why.
The future of Inspector
This is the biggest change coming: Inspector is going to be built in to MTGATracker, with all data stored locally.
This change will hopefully have a pretty small impact on the end-user experience (and hopefully a net positive one), but represents a massive shift in technological architecture for MTGATracker. So far, MTGATracker: Inspector has been a web-based tool, meaning that you access it through your browser. This will not be the case moving forward; instead, Inspector will be a tool you access from within MTGATracker itself, with all of your personal data stored on your hard drive, rather than in a database somewhere in “"”the cloud.””” The end result is an Inspector that looks nearly identical to the Inspector you’re used to, but with a nearly completely rewritten underlying codebase.
Users will have a generous time period to collect their data from our systems to be stored locally, with a quick press of a single button. Here’s a gif of what the import process should look like:
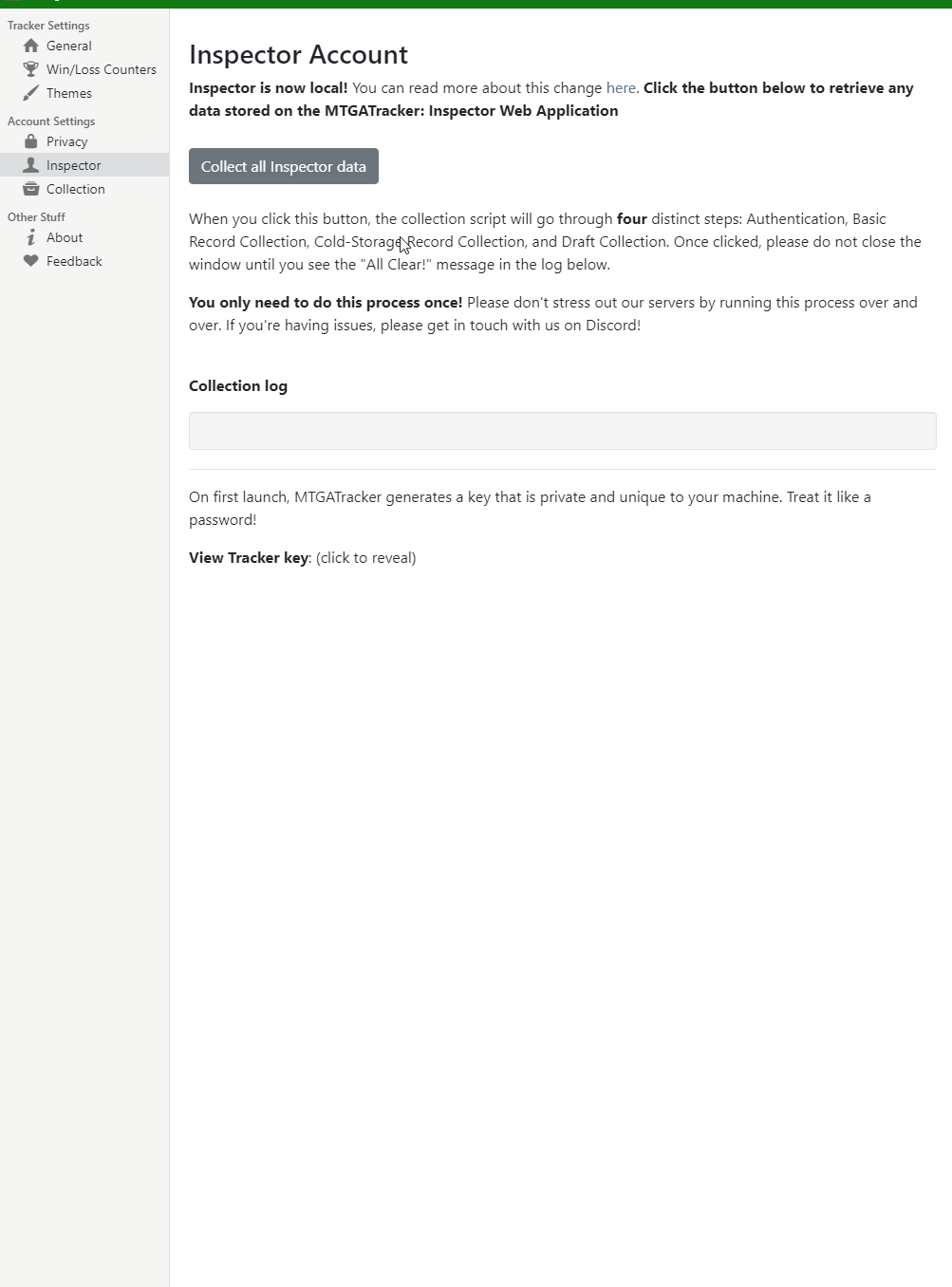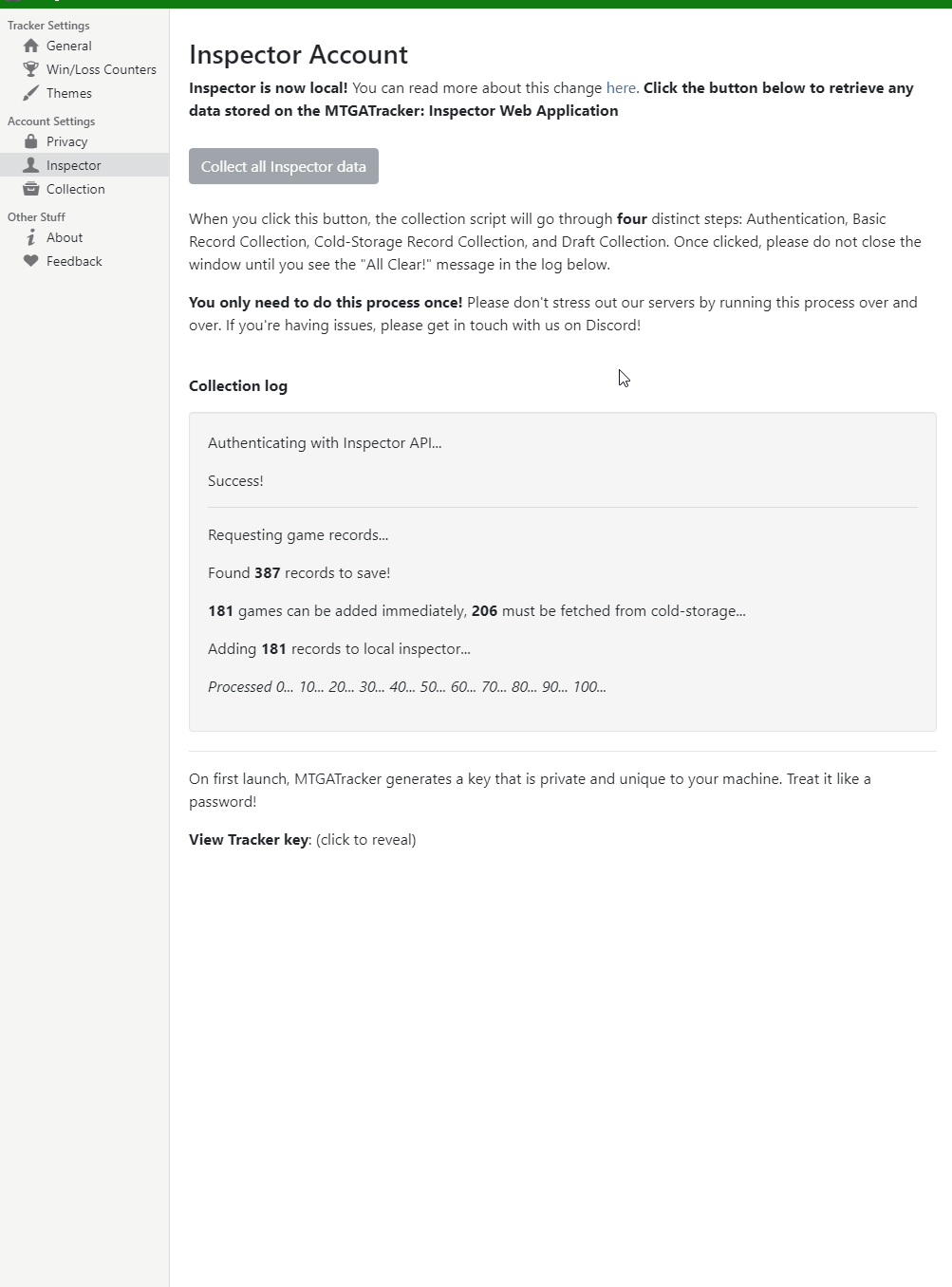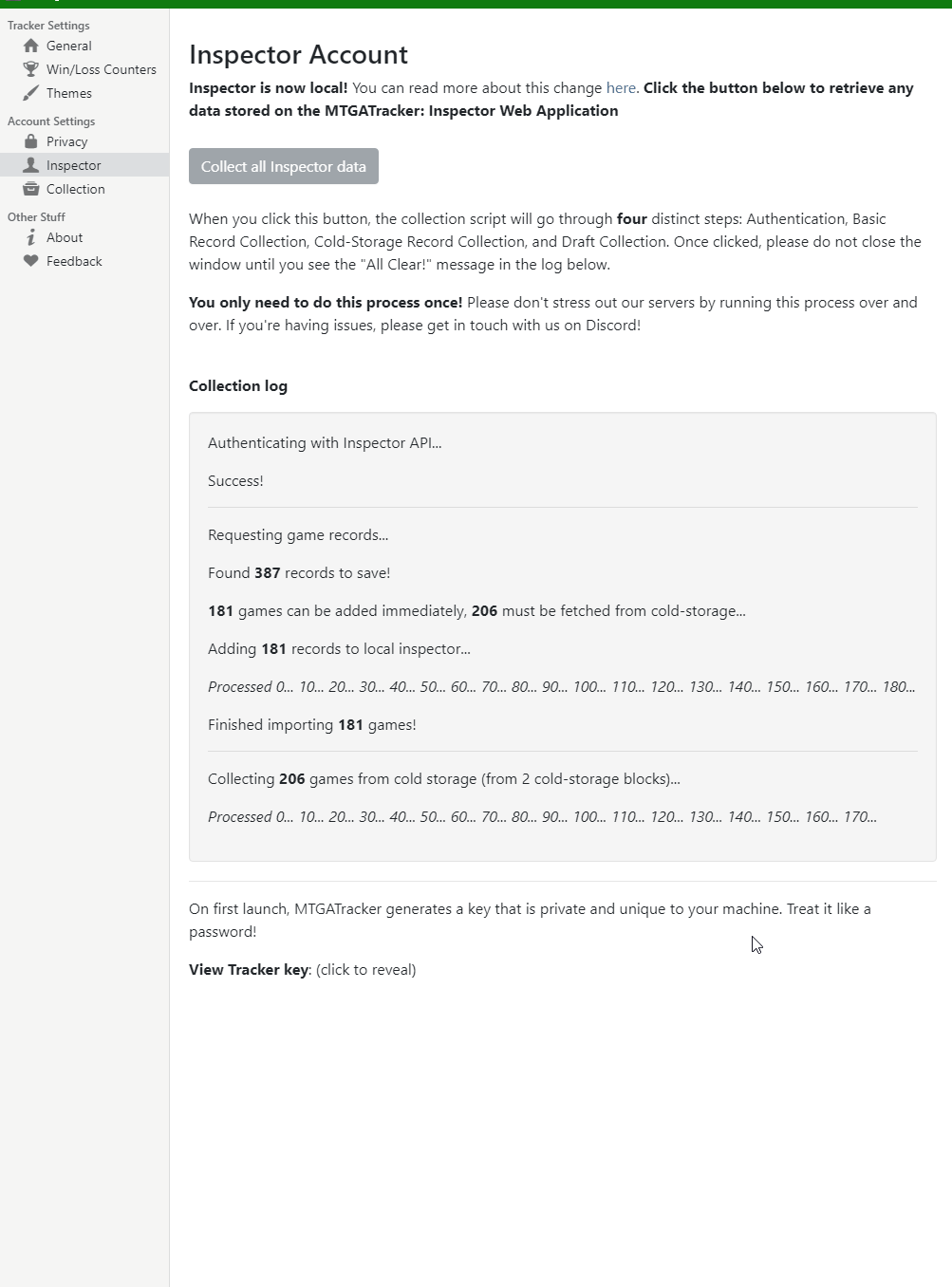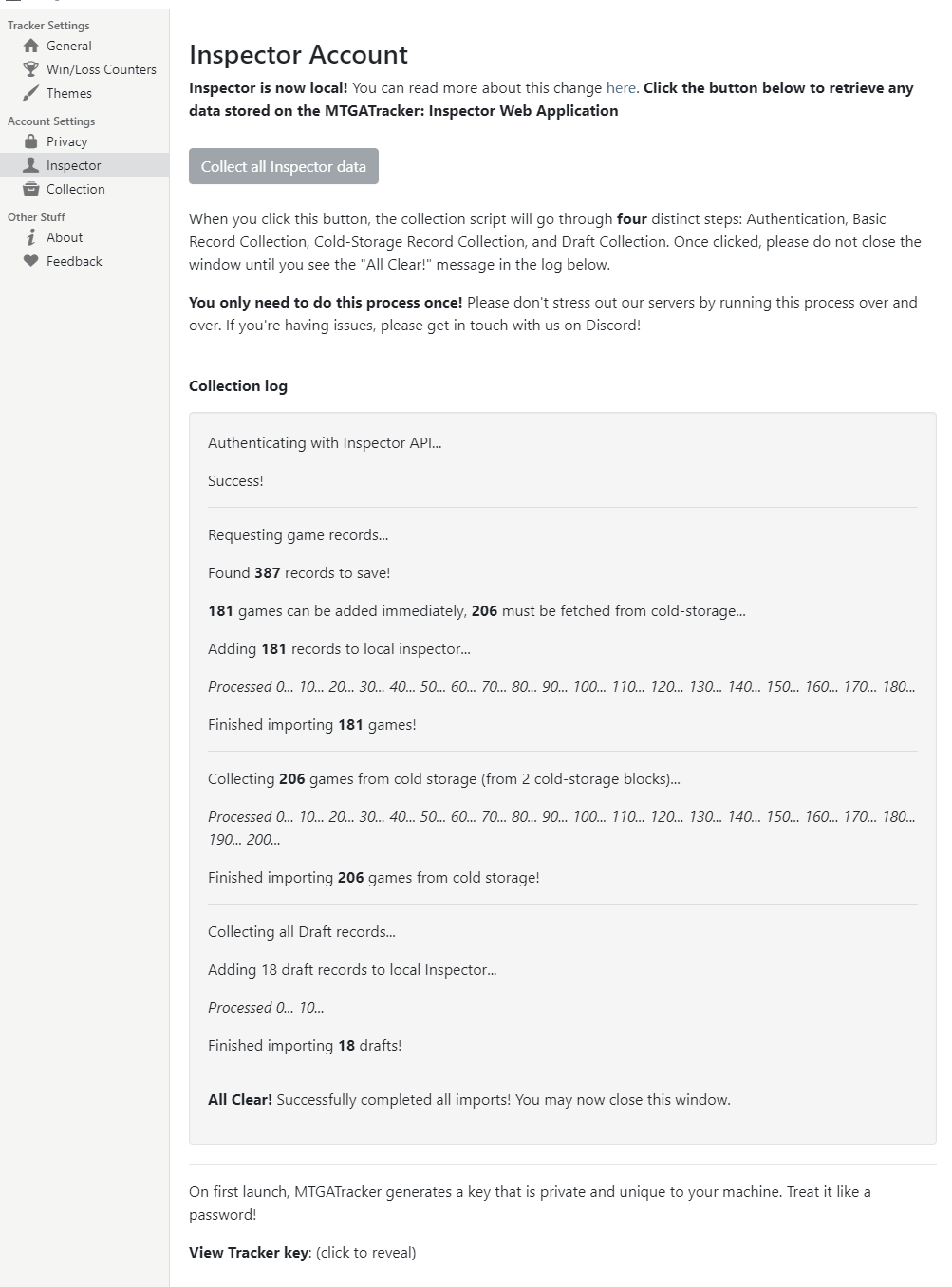
TL:DR; 5.0.0 is coming. Make sure to update before Dec 1st, and then smash that mf import button
But why?
We’re making this change for a few reasons. First- with over a million game records, many including action log histories: frankly, we’re drowning in data (awesome!), and it’s getting pretty expensive to maintain (…less awesome). We want to make sure MTGATracker can be sustainable as a tool that remains free, open source, and ad-free, and our costs are trending in the wrong direction to meet this goal (largely due to the amount of data we keep hot in our database cluster). We currently get away with spending a little less than a hundred dollars each month on our DBaaS, but our contract is set at a hard limit of 8GB (with the next tier of service starting at $180 / month), yet the database currently looks like this:

If you’ve been hanging out in Discord, you’ve probably heard the terms “cold storage” thrown around, which is in reference to any kind of data storage that is cheaper than running a hot database cluster. This was a stopgap put in place that I was hoping would extend our data runway more significantly than it actually ended up doing. For the last few weeks, we’ve been doing daily database “compact and failover” cycles on the cluster in order to reclaim disk space, yielding only about 1GB (of the current 8GB limit) each cycle. Today (11/28) when we did this cycle, we reclaimed less than 400MB, which wasn’t even enough to get the database out of the “warning” state. Even if we were to get much more aggressive with cold storage policies (which could also lead to worse user experiences), it’s clear that this strategy isn’t sustainable without increasing the costs of operation.
Another reason we’ve decided to pursue this change is that we believe it will result in a much faster and much better experience for end users. Filtering through 1.1 million game records to find your ~500 games is much slower than just keeping your ~500 games separated on your own disk.
The final reason that we’re moving to a locally-stored data policy is much more simple: it will give users better control over their data. You’ll no longer be relying on MTGATracker online services to access your inspector data; our database can get hard capped, go down, or catch on fire for all you care; your data will be accessible from your own hard drive directly. And with the next iteration of MTGATracker, we won’t need to keep (or even see) your data (though it’s nice that you trust us enough to share)- so going forward, we just simply won’t. It’s been fun getting to write posts analyzing the plethora of data we’ve so far had access to (like the shuffler post), but these posts don’t outweigh the primary concern of giving MTGATracker users a positive experience. (Furthermore, as we ventured deeper into meta analyses, I began to more seriously ponder the “goodness” of doing so in the first place. In the end, I’ve personally decided that I don’t want to be responsible for any efforts to “solve” the meta more quickly. A solved meta is generally a boring meta.) We’ll likely tighten up our privacy policy after the new changes take effect to show that we’re no longer really collecting data at all, besides just enough to keep bumping our “games tracked” and “unique user” counters on the homepage.
It can’t all be good though…
There probably are going to be some hiccups in this transition. For example, we’ve identified 156 MTGATracker users whose data come from multiple machines–or, about 1.7% of our lifetime userbase. (Note: an earlier version of this post incorrectly identified this number of users as 13. After re-running the query, the number is still low, but more significant than originally estimated.) This change is going to be a problem for them, as Inspector previously (in theory) would aggregate results from many machines into one place. Now, since results will be stored locally on each machine, that won’t be a feature we get for free anymore, and we’ll again have to come up with a solution for that problem sometime in the future. If you’re one of those 13 and you’re immediately impacted by this change, get in touch with Spencatro on Discord.
Another small loss is that you won’t be able to pull up your Inspector profile from anywhere anymore. (I personally loved the idea of pulling up Inspector on my phone to show my arena record off to folks at FNM for example, but in practice I don’t think I’ve ever done this, except to demo the tech.) This is a loss that I hope will hurt me personally more than any of our individual users.
While I’m not going to make promises right now, I find it likely that, at some point in the future, we’ll bring back an opt-in only version of Inspector that is built around full encryption of data. This would mean that users would be able to put their data in our systems if they so desire, but in a way that only their account would have the ability to decrypt & read the data. This would preclude us from snooping, even if we wanted to, and represents a tech challenge that I personally am excited to try to solve.
So, when is this all going down?
This is the scary part: we need to shut off the data ingestion pipeline way quicker than I’d personally like to. The target is to have all data ingestion halted by Dec 1st, 2018, but the database may become hard-capped at any point leading up to then. After the ingestion is stopped, we’ll try to keep whatever is already in the database hot for retrieval, with a goal of moving all data into cold storage by early March, 2019.
I know the timing here is pretty tight, and I want to personally apologize to any of our users negatively impacted; trust me when I say I am rushing as fast as I can to get 5.0.0 ready in an attempt to make sure there’s no functional downtime. As always, thanks in advance for your patience as we all learn how to grow together! Track on, y’all!